
|
| VAT sets a new state-of-the-art in few-shot segmentation, and attains state-of-the-art performance for semantic correspondence as well. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| VAT sets a new state-of-the-art in few-shot segmentation, and attains state-of-the-art performance for semantic correspondence as well. |
| This paper presents a novel cost aggregation network, called Volumetric Aggregation with Transformers (VAT), for few-shot segmentation. The use of transformers can benefit correlation map aggregation through self-attention over a global receptive field. However, the tokenization of a correlation map for transformer processing can be detrimental, because the discontinuity at token boundaries reduces the local context available near the token edges and decreases inductive bias. To address this problem, we propose a 4D Convolutional Swin Transformer, where a high-dimensional Swin Transformer is preceded by a series of small-kernel convolutions that impart local context to all pixels and introduce convolutional inductive bias. We additionally boost aggregation performance by applying transformers within a pyramidal structure, where aggregation at a coarser level guides aggregation at a finer level. Noise in the transformer output is then filtered in the subsequent decoder with the help of the query’s appearance embedding. With this model, a new state-of-the-art is set for all the standard benchmarks in few-shot segmentation. It is shown that VAT attains state-of-the-art performance for semantic correspondence as well, where cost aggregation also plays a central role. |
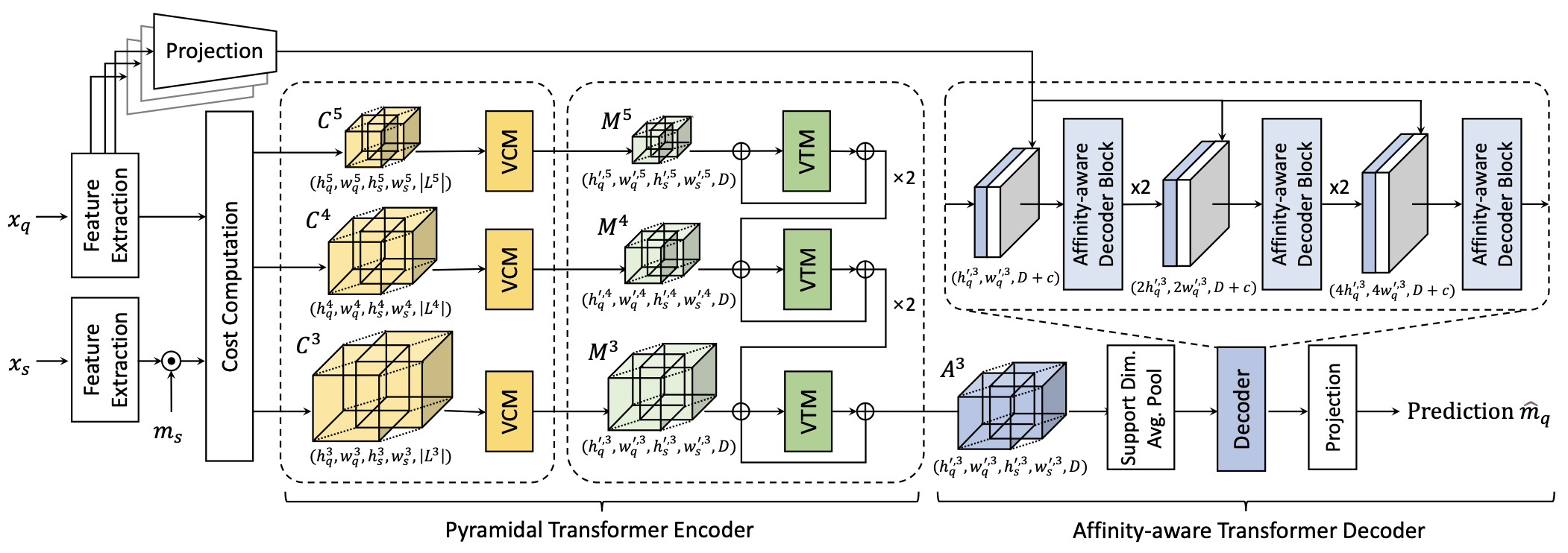
|
| Our networks consist of feature extraction and cost computation, pyramidal transformer encoder, and affinity-aware transformer decoder. Given query and support images, we first extract all the intermediate features extracted from backbone network and compute multi-level correlation maps. They then undergo the encoder to aggregate the matching scores with transformers in a pyramidal fashion. The decoder finally predicts a mask label for a query image. |
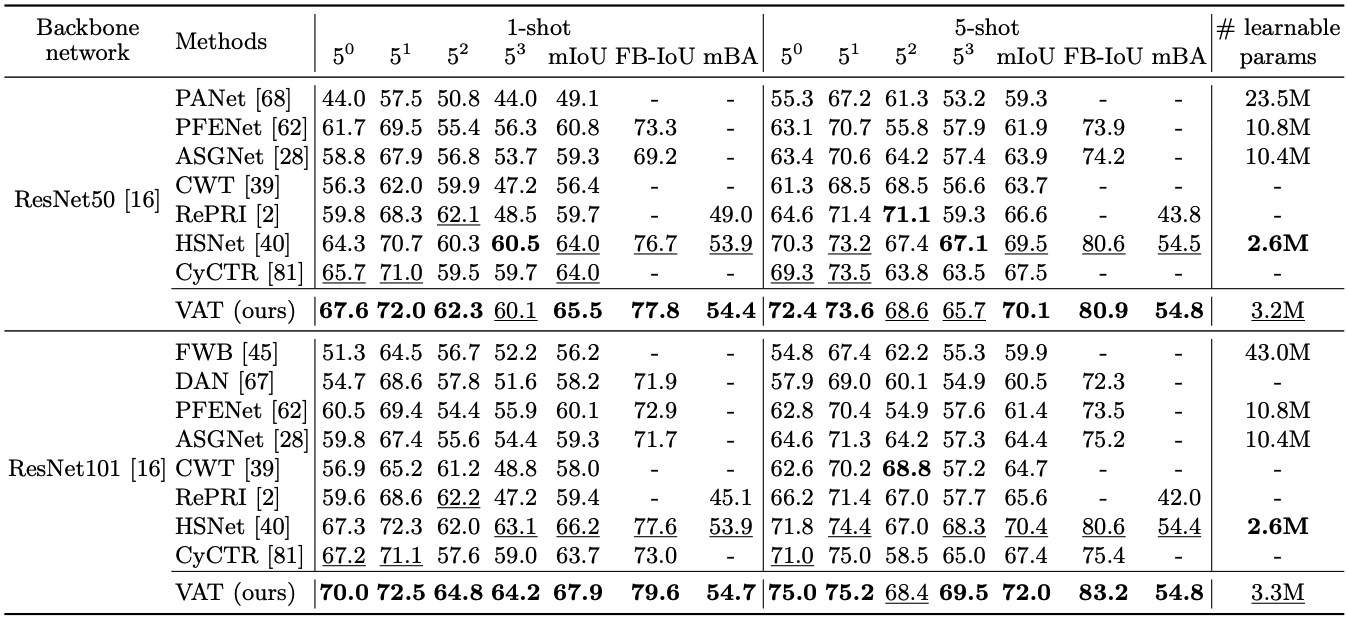 |
| Table 1. Performance on PASCAL-5i in mIoU and FB-IoU. Numbers in bold indicate the best performance and underlined ones are the second best. |
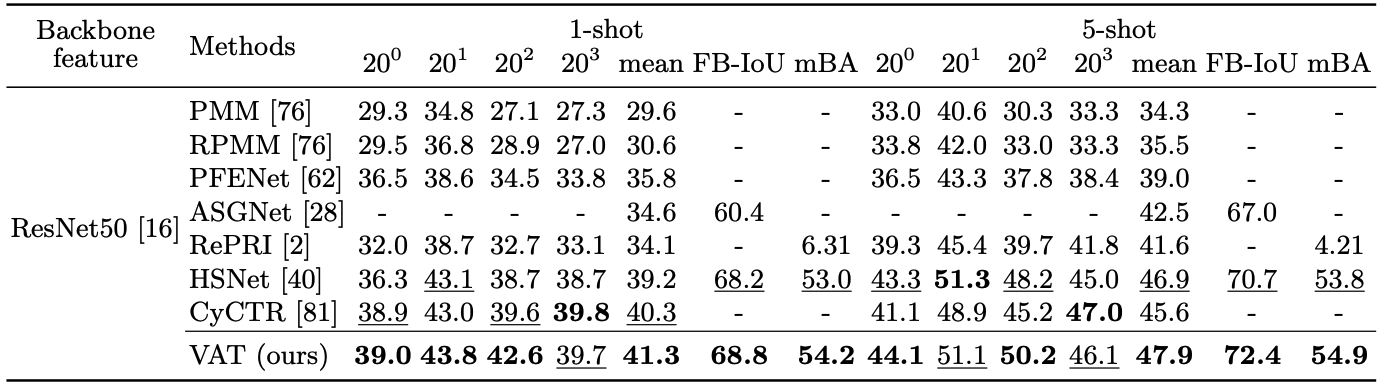 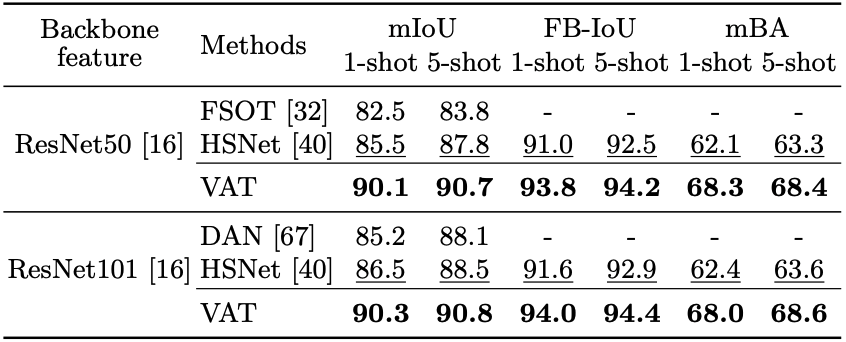 |
| Table 2. Performance on COCO-20i in mIoU and FB-IoU (left). Mean IoU comparison on FSS-1000 (right). |
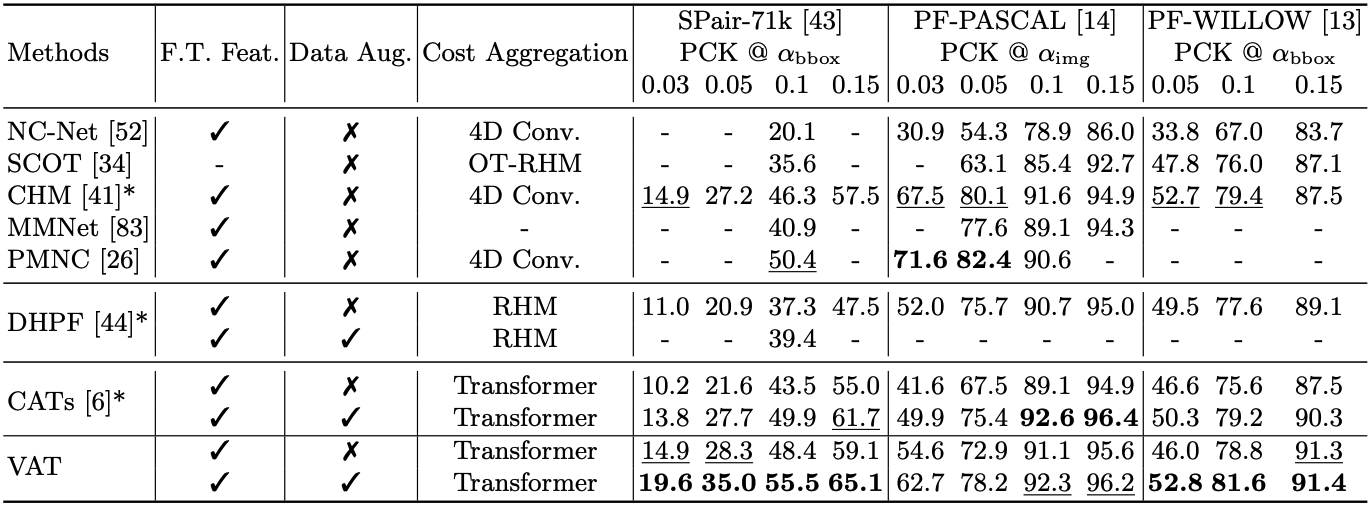 |
| Table 3. Quantitative evaluation on SPair-71k benchmark. |
 |
| Figure 1. Qualitative results on COCO-20i. |
 |
| Figure 2. Qualitative results on SPair-71k. |
 |
S. Hong*, S. Cho*, J. Nam, S. Lin, S. Kim Cost Aggregation with 4D Convolutional Swin Transformer for Few-Shot Segmentation ArXiv Google Scholar |
Acknowledgements |